Bibliometric Analysis¶
The Bibliometrics class provides tools for a bibliometric analysis of Web of Science datasets.
Members:
titleClean: Clean title names (remove punctuation, stopwords and numbers).
fundingClean: Clean funding agencies (remove grant number and punctuation) and group similar names.
cit_by: Computes number of citations as function of the chosen parameter.
cit_num: Computes number of citations per number of occurences in the chosen parameter.
pub_by: Computes number of publications as function of the chosen parameter.
pub_num: Computes number of publications per number of occurences in the chosen parameter.
The definition of all these functions can be found at the bottom of that page.
All examples on this page are computed using a dataset of research publications citing at least one of the papers associated with the software ABINIT between its creation and 2019. The exact dataframe used can be found in the test folder of our library. Those citations are available on the Web of Science website and the data was converted to a Pandas dataframe with the methodology described in the WoS Preparation page.
To start working with the pyBiblio package, you first have to import the package and create an object of the class Bibliometrics like so:
from pybiblio import Bibliometrics
analysis = Bibliometrics()
Number of citations per year¶
The function cit_by is handy to quickly compute the number of citations depending on the values of a certain column. A good example of this function is to calulate the number of citations per year with the following line of code:
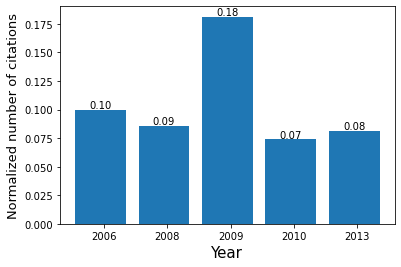
citYear = analysis.cit_by(data, by = 'PY', n = 5, norm = True, sort = False)
“PY” is the WoS tag for the year of publication so the function will only consider this column to compute the number of citations. Null values in the chosen column will be deleted. By setting n=5, the above line of code returns a Pandas dataframe with 5 rows of highest frequency. Frequency values will be normalized over the total number of citations as the binary parameter norm is True and rows are sorted by year and not by frequency because the parameter sort is False.
Here is the result dataframe:
PY |
freq |
|---|---|
2006 |
0.0993408 |
2008 |
0.0854208 |
2009 |
0.181217 |
2010 |
0.0737779 |
2013 |
0.0812602 |
The following lines of code help visualize the results in the previous table by graphing them in a bar plot:
#import libraries
import numpy as np
import matplotlib.pyplot as plt
r1 = np.arange(len(citYear))
plt.bar(r1, citYear.freq) #barplot
plt.xticks([r + 0.05 for r in range(len(citYear))], citYear.PY) #year labels
plt.xlabel("Year", fontsize = 15)
plt.ylabel("Normalized number of citations", fontsize = 13)
#annotate the frequency values
for x,y in zip(r1, citYear.freq):
label = "{:.2f}".format(y)
plt.annotate(label, (x,y+0.0015), ha='center')
Number of publications by funding agency¶
The function pub_by is similar to the function cit_by and has the same parameters, but computes the number of publications instead of the citations. In this example, we compute the number of publications by funding agency. The WoS tag “FU” contains, for each paper, a string of all different funding agencies and their corresponding grant number separated by a semicolon. However, a lot of agencies are written in different manners. For example, “DOE”, “Department of Energy”, “US Department of Energy” and “US DOE” all represent the same agency. To minimize those difference, we created a file with common variations of over five hundred of the most recurrent funding agencies in the field of Density Functional Theory.
The text file ‘FU.csv’ consists of rows in the format: derived name of the funding agency, official name.
Here is an example of the file format:
US DOE,US DEPARTMENT OF ENERGY
DOE,US DEPARTMENT OF ENERGY
We would appreciate any contributions to this file, as it will benefit any user to achieve more precise results. Please contact mcd0029@mix.wvu.edu if you would like to contribute.
The following line of code will compute the number of publications per funding agency:
pubFunding = analysis.pub_by(data, by = 'FU', dpc = ['DI'], n = 10, norm = False, sort = True)
The following table shows the results of the above line of code. The dpc parameter holds a list of column names considered for removing duplicates. In this example, papers with identical DOI numbers will be removed before any computation is performed. When several columns are mentioned, observations will be removed if they have only one match. The parameter norm is set to False, so the number of publications are not normalized and the sort parameter set to True means that the results will be sorted in descending order.
The results are listed below:
FU |
freq |
|---|---|
US NATIONAL SCIENCE FOUNDATION |
287 |
US DEPARTMENT OF ENERGY |
220 |
RESEARCH AND DEVELOPMENT PROGRAM OF CHINA |
157 |
RESEARCH FOUNDATION DFG |
106 |
EUROPEAN UNION |
75 |
GENCI |
68 |
OFFICE OF NAVAL RESEARCH |
62 |
FONDS DE LA RECHERCHE SCIENTIFIQUE DE BELGIQUE |
57 |
RUSSIAN FOUNDATION FOR BASIC RESEARCH |
54 |
NATURAL SCIENCES AND ENGINEERING RESEARCH COUNCIL OF CANADA |
47 |
Number of citations as function of the number of words in titles¶
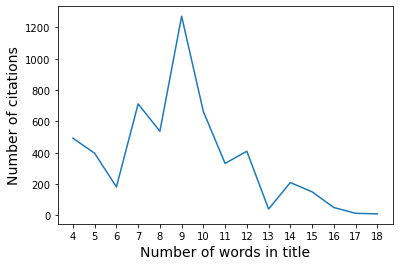
The functions cit_num and pub_num compute the number of different occurences (like number of different authors, countries or words) against the number of citations or publications (respectively). A good example is the following line of code:
citTitle = analysis.cit_num(data, by = 'TI', n = 15, subset = ['density', 'theory'], sep = ',', norm = False, sort = False)
When the tag ‘TI’ is passed in the by parameter, the column holding titles is sent to the function titleClean that will remove any punctuation, symbols, hyperlinks, digits and stop words. The result will be a string of the remaining words joined by the separator chosen (in this case, a comma but the default is a semi-colon). To make it more clear, the title “Authorship and citation cultural nature in density functional theory from solid state computational packages” will return “authorship;citation;computational;cultural;density;functional;nature;packages;solid;state;theory”. Keeping the same example, the number of different occurences will be 11.
Another useful parameter available on all functions in the bibliometrics class is the subset parameter. This will help subset your data, before processing, according to the elements of the list. In the above line of code, we have two elements, meaning that a title will only be taken into account if both words “density” and “theory” are elements of the title. This parameter is case insensitive.
With some additional lines of codes, we can easily plot the results and determine the lengths of titles yielding the highest number of citations.
plt.plot(citTitle.numTI, citTitle.freq)
plt.xlabel("Number of words in title", fontsize=14)
plt.ylabel("Number of citations", fontsize=14)
plt.xticks(citTitle.numTI)
Other Applications¶
WoS tags are required by a function if you are working with the number of citations, the title or the funding agencies. However, the functions explained above can return a result for any chosen column that has a type float, int or string.
Let’s say that we manually add a column “topic” that will hold the general subject of a paper. This is not a Wos tag but the following line will return a pandas dataframe in the same manner as any other column:
analysis.pub_by(data, by = 'topic')
-
class
pybiblio.bibliometrics.Bibliometrics¶ This class provides a bibliometric implementation for Web of Science datasets.
- Members:
titleClean: Clean title names (remove punctuation, stopwords and numbers).
fundingClean: Clean funding agencies (remove grant number and punctuation) and group the ones with similar names.
cit_by: Computes number of citations as function of the chosen parameter.
cit_num: Computes number of citations per number of occurences in the chosen parameter.
pub_by: Computes number of publications as function of the chosen parameter.
pub_num: Computes number of publications per number of occurences in the chosen parameter.
-
cit_by(df, by, n=0, subset=[], dpc=[], sep=';', sort=True, norm=False)¶ Computes number of citations as function of the chosen parameter ‘by’.
Returns a pandas dataframe with 2 columns: value and frequency.
Example: number of citations by year, number of citations per author.
- Parameters:
df is a pandas dataframe.
by is a string of the column name chosen.
n is an integer to select the n rows with largest values.
subset is a list of items to consider in the chosen column.
dpc is a list of column names to consider to remove duplicates.
sep is the separator (e.g. for China;USA in countries)
sort is a binary variable. If true, the dataframe returned is sorted by decreasing frequency value
norm is a binary variable. If true, frequency values are normalized by the total number of citations.
-
cit_num(df, by, n=0, subset=[], dpc=[], sep=';', sort=True, norm=False)¶ Computes number of citations as function of the number of occurences for chosen parameter ‘by’.
Returns a pandas dataframe with 2 columns: value and frequency.
Example: number of citations per number of authors in a paper.
- Parameters:
df is a pandas dataframe.
by is a string of the column name chosen.
n is an integer to select the n rows with largest values.
subset is a list of items to consider in the chosen column.
dpc is a list of column names to consider to remove duplicates.
sep is the separator (e.g. for China;USA in countries)
sort is a binary variable. If true, the dataframe returned is sorted by decreasing frequency value
norm is a binary variable. If true, frequency values are normalized by the total number of citations.
-
fundingClean(FU, sep=';')¶ Clean all funding agencies in the list FU.
Function called by cit_num, cit_by, pub_num and pub_by if the parameter is FU.
For each element of the list, remove grant number, punctuation and symbols, strip whitespaces.
Agencies are compared with known data to group similar names.
Returns a list of strings in the same format as FU to keep the order.
-
pub_by(df, by, n=0, subset=[], dpc=[], sep=';', sort=True, norm=False)¶ Computes number of publications for chosen parameter ‘by’.
Returns a pandas dataframe with 2 columns: value and frequency.
Example: number of publications per year.
- Parameters:
df is a pandas dataframe.
by is a string of the column name chosen.
n is an integer to select the n rows with largest values.
subset is a list of items to consider in the chosen column.
dpc is a list of column names to consider to remove duplicates.
sep is the separator (e.g. for China;USA in countries)
sort is a binary variable. If true, the dataframe returned is sorted by decreasing frequency value
norm is a binary variable. If true, frequency values are normalized by the total number of citations.
-
pub_num(df, by, n=0, subset=[], dpc=[], sep=';', sort=True, norm=False)¶ Computes number of publications as function of the number of occurences for chosen parameter ‘by’.
Returns a pandas dataframe with 2 columns: value and frequency.
Example: number of publications per number of authors in a paper.
- Parameters:
df is a pandas dataframe.
by is a string of the column name chosen.
n is an integer to select the n rows with largest values.
subset is a list of items to consider in the chosen column.
dpc is a list of column names to consider to remove duplicates.
sep is the separator (e.g. for China;USA in countries)
sort is a binary variable. If true, the dataframe returned is sorted by decreasing frequency value
norm is a binary variable. If true, frequency values are normalized by the total number of citations.
-
titleClean(TI, sep=';')¶ Clean all titles in the list TI.
Function called by cit_num, cit_by, pub_num and pub_by if the parameter is TI.
Converts all titles to lowercase, remove punctuation, symbols and numbers, removes stopwords defined in the NLTK package and strip whitespaces.
Returns a string of leftover words separated by a semicolon.